服务熔断
分布式系统中的服务熔断是一种容错保护机制,其核心目标是通过**快速失败(Fail Fast)**防止服务间的级联故障,避免系统雪崩。它的设计灵感来源于电路中的熔断器:当电路过载时,熔断器自动断开,保护整个系统。
核心作用
-
故障隔离
当某个下游服务响应超时或异常率过高时,熔断器会立即切断对该服务的调用,避免资源(如线程、连接)被长期占用。 -
快速失败
熔断后,请求直接返回预设的降级结果(如错误提示、缓存数据),减少无意义的等待和资源消耗。 -
自动恢复
熔断器会周期性检测下游服务是否恢复(如每隔30秒),逐步尝试恢复调用,避免人工干预。 -
防止雪崩
通过阻断对故障服务的持续调用,避免局部故障扩散到整个系统。
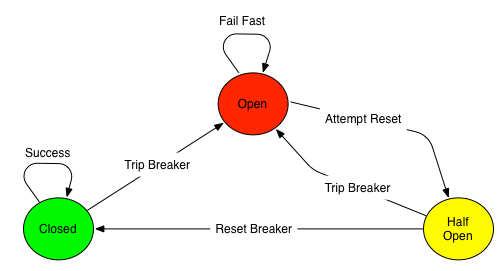
工作原理(状态机模型)
熔断器通常包含三种状态,通过阈值和策略自动切换:
-
Closed(关闭)
- 默认状态,允许正常调用。
- 触发熔断:当失败率(如超时、异常)超过阈值(如50%),或连续失败次数达到阈值,进入
Open状态。
-
Open(开启)
- 拒绝所有请求,直接返回降级结果。
- 进入半开:经过预设的休眠时间(如5秒),进入
Half-Open状态,试探性恢复少量请求。
-
Half-Open(半开)
- 允许少量请求通过,用于探测下游服务是否恢复。
- 恢复成功:如果试探请求成功率达到阈值(如80%),回到
Closed状态。 - 恢复失败:如果仍失败,回到
Open状态,延长熔断时间。
典型应用场景
-
依赖服务不可用
例如,支付服务宕机时,电商订单服务通过熔断直接返回“支付繁忙”提示,而非无限等待。 -
高延迟导致资源耗尽
若用户服务响应变慢,熔断器阻止前端持续调用,避免线程池被占满,影响其他功能。 -
突发流量冲击
在秒杀活动中,熔断器可保护核心服务不被过载的次要请求拖垮。
实现工具
- Netflix Hystrix:最早的熔断实现,提供线程隔离、熔断、降级等功能。
- Resilience4j:轻量级熔断库,支持Java函数式编程。
- Sentinel:阿里巴巴开源的流量控制组件,支持熔断、限流、降级。
- Spring Cloud Circuit Breaker:抽象层,支持Hystrix、Resilience4j等多种实现。
配置参数示例
1# Resilience4j 配置示例
2resilience4j.circuitbreaker:
3 instances:
4 paymentService:
5 failureRateThreshold: 50% # 触发熔断的失败率阈值
6 minimumNumberOfCalls: 10 # 计算阈值的最小请求数
7 slidingWindowType: COUNT_BASED
8 slidingWindowSize: 20 # 统计最近20次请求的失败率
9 waitDurationInOpenState: 30s # Open状态持续时间
10 permittedNumberOfCallsInHalfOpenState: 5 # 半开状态允许的试探请求数
最佳实践
- 合理设置阈值:根据业务容忍度调整失败率和超时时间。
- 监控与告警:实时监控熔断状态,及时排查根本原因。
- 降级策略:熔断后返回缓存数据、默认值或队列化请求。
- 结合重试机制:在熔断前可对偶发错误进行有限次重试(但需注意幂等性)。
服务熔断是构建弹性分布式系统的关键机制,需与服务降级、限流、超时控制等配合使用,共同保障系统高可用。